|
1
|
|
|
2
|
- We’re part of the Model-Driven Development (MDD) team in the Rational
Software Division of the IBM Software Group
- CDT is the core C++ component of Rational Software Architect
- The C++ component includes visualization of code as UML as well as
transformation of UML to C++
- We need an accurate, complete DOM that allows programmatic code change
- Since do both Java and C++ we’d like the architectures of the JDT and
CDT to be “similar”.
|
|
3
|
- Started work on parser in Dec. 2002
- Considered a number of options but settled on a handwritten parser
- Needed smart control over ambiguities in C/C++
- Needed to support a number of clients with different needs
- Similar in approach to newer versions of gcc.
- First contributed in 1.1 for CModel replacing previous JavaCC-based
parser
- Added Indexing and Search as client in 1.2
- Replaced previous ctags-based index (not without issue)
- Numerous clients in 2.0, including content assist, F3, type browsers
|
|
4
|
- We had concern over scalability of AST
- Settled on a callback-based architecture
- Clients created only the data that they needed
- Client would pass in a requestor to the parser and the parser would pass
in parse info as the parse progressed
- Despite the names, the IAST* parse info does not form a proper AST
- Client would also be responsible for passing in ScannerInfo
- Compiler command line arguments that affect parsing
- Include paths, macro defs
- Needed to properly parse
|
|
5
|
- Pretty accurate parse information (usually)
- Content assist worked really well for C and C++
- Accurate out line view
- Accurate search results, F3
- Ability to generate type info for class and hierarchy browsers
- Flexibility for clients
- Enabled us to pile on the clients in 2.0
|
|
6
|
- Performance
- Assumed parse times would be quick, < 1 sec
- Finding parse times usually in 2-4 second range
- Index takes a lot of time, memory, and CPU power to generate
- Content assist times out regularly
- Hard to provide accurate results consistently
- F3 and content assist often produce no results
- Need for accurate ScannerInfo often hard to satisfy
- Scalability to large projects
- Problems only worsen when project grows
- Index times longer than already long build times
- ScannerInfo different for different files in project
|
|
7
|
- Although flexible, the callback mechanism was hard to define
- Unable to provide all information that every possible client would
require
- Often unable to determine parser context for certain constructs
- Clients had added complexity to manage their own data
- Parser had added complexity to provide enough data
- Need to address scalability
- Cut down on the amount of parsing we need to do
- Can we reuse parse results?
- Need data structures to help programmatically make changes to the source
code
|
|
8
|
- The DOM is composed of the parser/scanner and three levels of data
- 1) Physical AST with mapping back through macro expansions to source
- 2) Logical Scope/Binding tree with cross translation unit indexing
- 3) AST Rewriter
- Firm up interfaces for DOM creation
- Navigate from Core Model to DOM
- Hide parser from clients (use core model)
- Allows us to play with how the DOM is created to improve scalability
|
|
9
|
- To reduce the fixed cost of a parse (preprocess, scan & syntax
matching) and to allow for lazy semantic evaluation
- Improve performance & reduce memory footprint of navigation
features
- To provide a “complete” physical AST which can make our clients aware of
preprocessor macro expansions in source code
- To provide better support for C
- Link-time resolution cross references
- Tailored implementation of parser/semantic bindings
|
|
10
|
- Given a file to parse, the AST Framework shall return an
IASTTranslationUnit which then can be traversed or visited
- The IASTNode interface hierarchy represent constructs in the C/C++
grammar.
- long x; /* IASTSimpleDeclaration with 1 IASTDeclarator */
- long y(); /*
IASTSimpleDeclaration with 1 IASTFunctionDeclarator */
- int f() { return sizeof( int ); }
/* IASTFunctionDefinition */
- Physical tree is unaware of any semantic knowledge
- Declaration before use (C++)
- Scoping
- Type compatibility
- lValue vs. rValue
- Allows for quick generation of syntax tree
- Only slight overhead to cost of scan & preprocess
|
|
11
|
- Logical elements are higher-level constructs that map onto a physical
IASTNode
- For 3.0 : IASTName#resolveBinding()
- long x; /* IASTName for x resolves to an IVariable */
- long y(); /* IASTName for y
resolves to an IFunction */
- int f() { return sizeof( int ); }
/* IASTName for f resolves to an IFunction*/
- Beyond 3.0 – IASTBinaryExpression could bind to an user defined operator
- Semantic errors return an IProblemBinding describing the error
- IASTTranslationUnit can be asked for all declarations or references of a
particular IBinding
- Bindings can be resolved completely lazily on request or in a full
traversal of the AST
- Indexer would require full binding resolution
- Most other clients do not require all bindings to be resolved
|
|
12
|
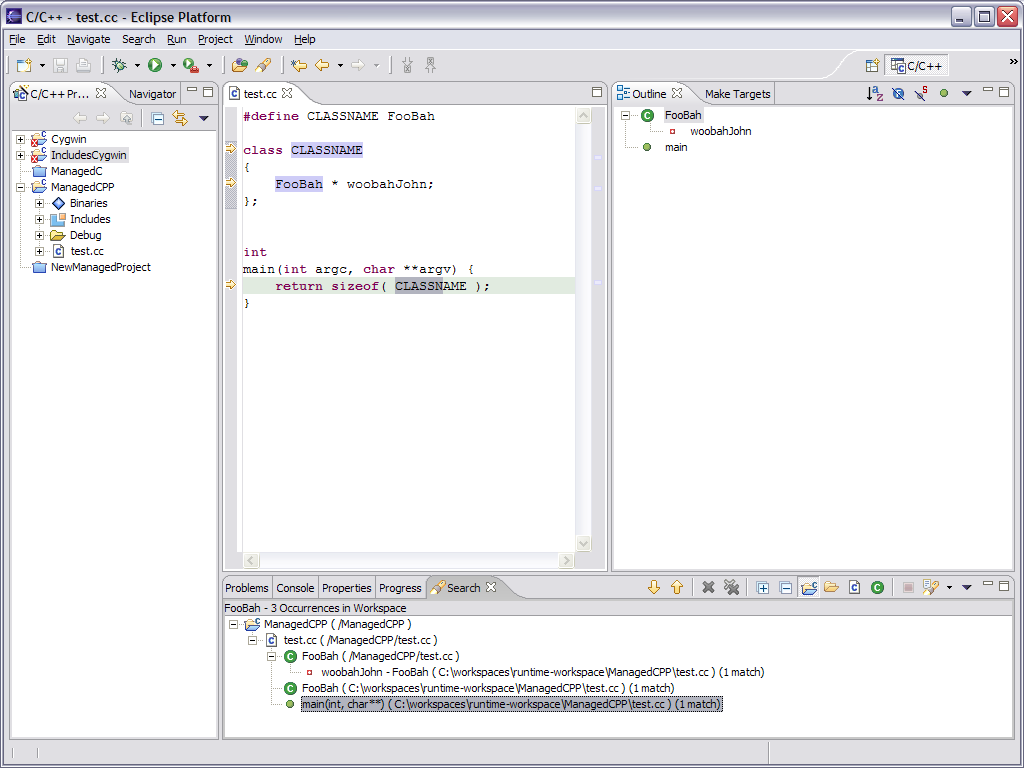
- Nearly all parser clients in the CDT are concerned with offsets
- Selection
- Search Markers
- Navigation
- Compare
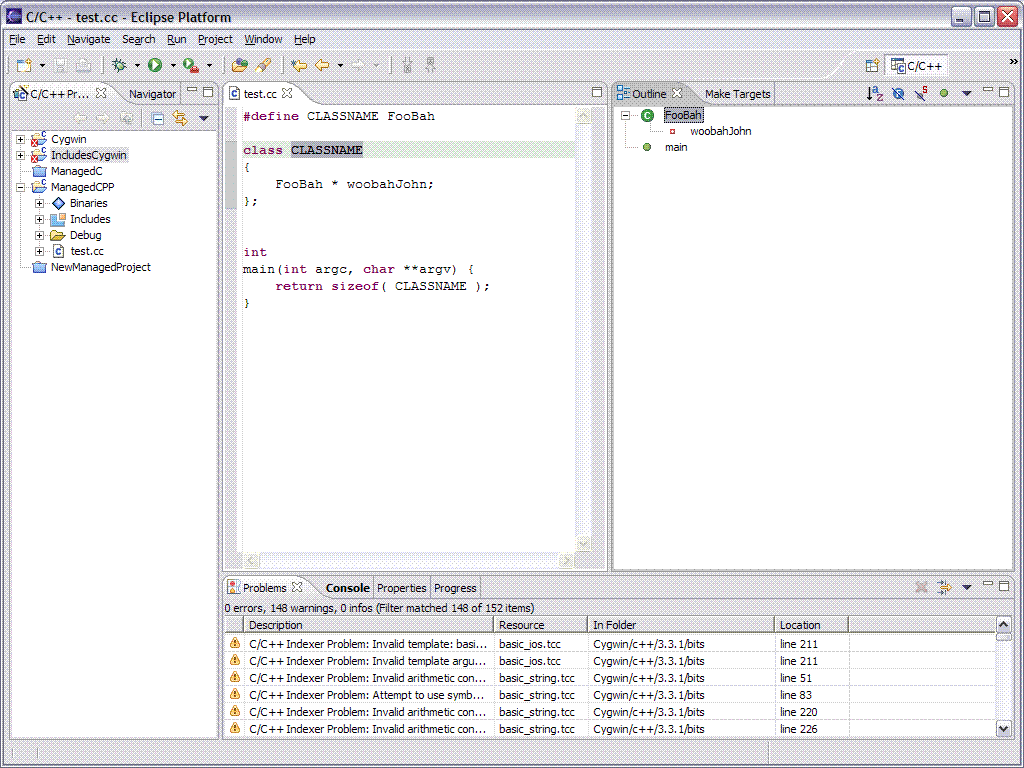
- Within a preprocessor macro expansion, our IScanner implementation
massages the offsets as tokens arrive
- However, the CDT 2.x AST Nodes are unaware as to whether or not they are
a result of a macro expansion
- This deficiency affects different clients differently.
|
|
13
|
|
|
14
|
|
|
15
|
|
|
16
|
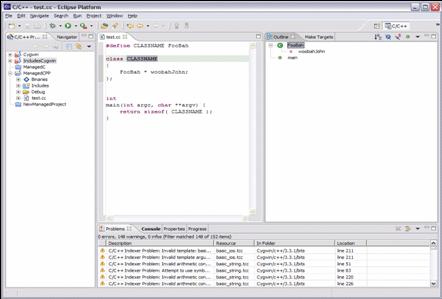
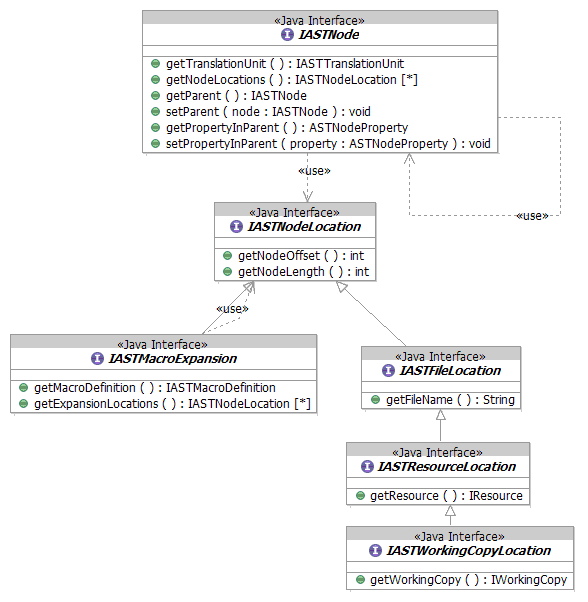
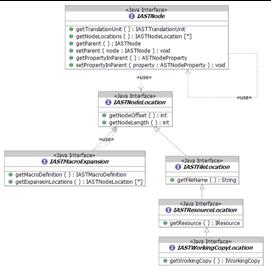
- Every node in the AST derives from IASTNode
- Every IASTNode provides a mechanism for resolving its location in the
physical AST
- External Header Files
- Resources
- Working Copies
- Macro Expansions
- getNodeLocations() returns an array of IASTNodeLocation, as a node may
span multiple locations (when macros are involved)
- Interpretation of macro expansion locations are up to the client
|
|
17
|
- Support for link-time bindings
- resolving function references in C
- Will greatly aid navigation/search features for this style of C code
- Refactoring/programmatic edit support will be difficult
- Definite candidate for “Preview” pane in refactoring
- Without full build-model to reference, resolution is heuristic-based
- Stricter emphasis upon providing custom implementation for C & GCC
- AST & supporting data structures will be more compact memory wise
- Syntax parsing will be more accurate
- Algorithms for semantic analysis in C are far less rigorous
- Should yield better performance for nearly all clients
|
|
18
|
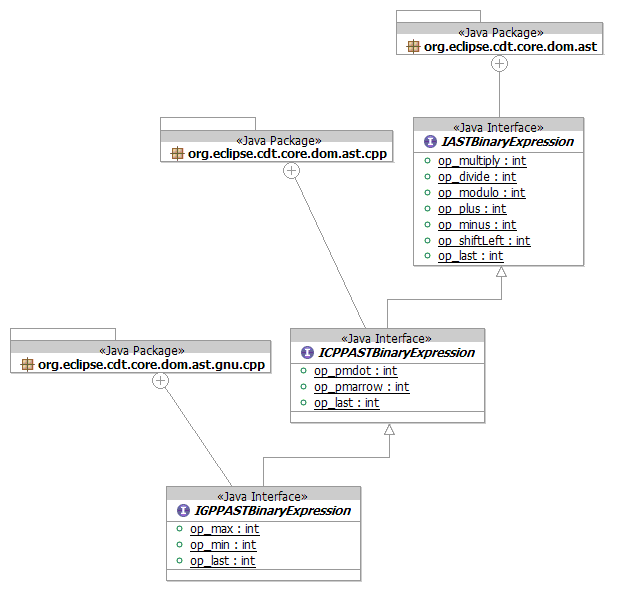
- Interfaces
- org.eclipse.cdt.core.dom.ast – Base interfaces that apply to both ANSI
C & ISO C++
- org.eclipse.cdt.core.dom.ast.c – C99 specific sub-interfaces
- org.eclipse.cdt.core.dom.ast.cpp – ISO C++ 98 specific sub-interfaces
- org.eclipse.cdt.core.dom.ast.gnu – GNU extensions that apply to both C
& C++
- org.eclipse.cdt.core.dom.ast.gnu.c – GNU extensions that apply to C
- org.eclipse.cdt.core.dom.ast.gnu.cpp – GNU extensions that apply to C++
- Implementations
- org.eclipse.cdt.internal.core.parser2 – supporting infrastructure
- org.eclipse.cdt.internal.core.parser2.c – C99 & GCC support
- org.eclipse.cdt.internal.core.parser2.cpp – ISO C++ 98 & G++
support
- Other variants may subclass C or C++ Source Code Parser and choose which
GNU extensions they wish to enable through a configuration interface
|
|
19
|
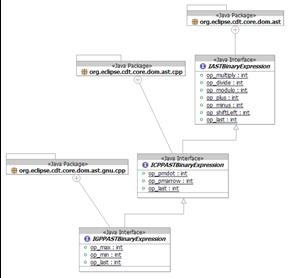
- C++ extends the common AST
- GNU C++ extends the C++
- C++ and C are unrelated outside of the common AST package
|
|
20
|
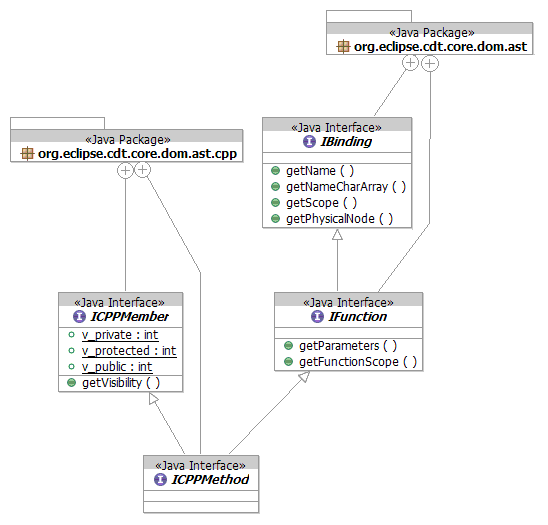
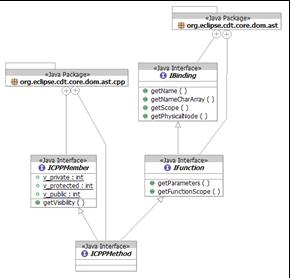
- C extends common
- C++ extends common
- Theoretically, new bindings could be added for future variants
|
|
21
|
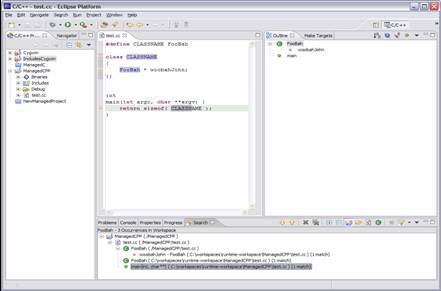
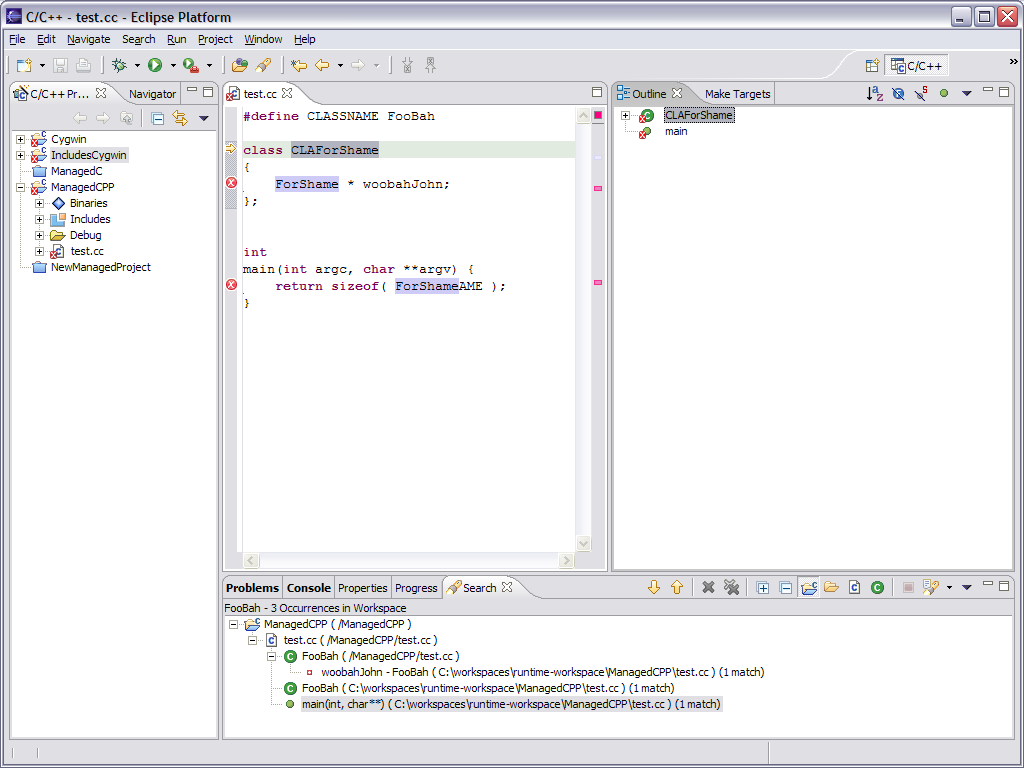
- AST Rewriter accepts requests to change AST
- Add (Insert/Set), Remove, Replace
- The new code can be a new AST Node or a String
- AST Rewrite gathers change requests and then executes
- Analyzes the change requests for validity
- Produces text edits that can be applied to documents to affect the
change
- The analysis can decide not to do a change because it is too hard
- E.g. when macros are involved
|
|
22
|
- We need to take some effort to minimize parsing within Eclipse
- C and C++ are mature languages : hence, larger source code bases
- Multiple clients parsing on resource-change events can cripple the
system
- A complex web of #include’s throughout the code base is difficult to
optimize per-parse without having knowledge of previous parses
- The Indexer is already parsing continually, we should be able to
leverage that information for all other clients that require saved-file
parse trees
- Since parsing can be a processor and memory-intensive operation, it is
difficult for the indexer to co-ordinate its priority vs. other parser
clients for system resources
- users requests an Open Declaration which competes against a running
indexer for memory & CPU
- Eventual Goal
- AST Service w/Index
- Incremental Parse
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}